Authors: Kai Sun, Peibo Duan, Yongsheng Huang, Nanxu Gong, and Levin Kuhlmann
Venue: ICLR 2026
Spiking Neural Networks, or SNNs, have long been attractive for neuromorphic and low-power AI because they process information through sparse, event-driven spikes rather than dense continuous activations. That makes them a promising fit for edge devices and resource-constrained settings. The problem is familiar: while SNNs are efficient, they still tend to lag behind conventional artificial neural networks in accuracy.
Our new paper from brAIn Lab, “Many Eyes, One Mind: Temporal Multi-Perspective and Progressive Distillation for Spiking Neural Networks,” introduces a new way to close that gap. The core idea is simple: if SNNs make decisions over time, then the supervision used to train them should also respect that temporal structure. That is the motivation behind MEOM.
Why this problem matters
A spiking neural network does not arrive at its prediction all at once. It accumulates information across timesteps. Earlier timesteps contain partial evidence, and later ones usually contain richer and more stable signals. This creates a practical challenge.
Existing knowledge distillation methods often use a strong ANN teacher to guide the SNN student. That helps, but prior temporal distillation approaches still apply the same teacher signal at every timestep. The paper argues that this is a mismatch: the student is evolving over time, yet the supervision remains static. At the same time, when inference is truncated early to save energy or reduce latency, predictions can become immature or inconsistent because the model has not fully accumulated temporal information.
In other words, previous methods miss two things:
- they do not provide enough temporal diversity in supervision, and
- they do not adequately train the model to stay reliable when inference is cut short.
The central idea of MEOM
MEOM stands for Many Eyes, One Mind. The name reflects the two key components of the method.
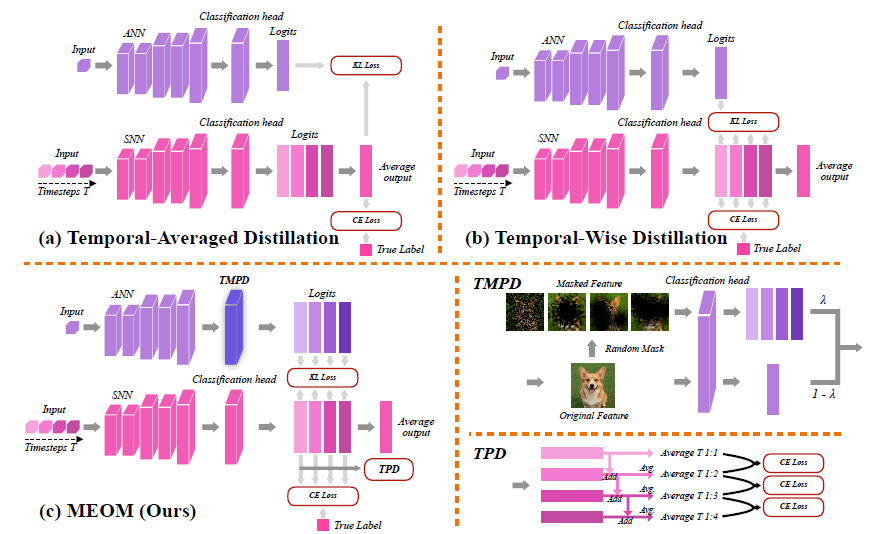
Many Eyes: Temporal Multi-Perspective Distillation
The first component, Temporal Multi-Perspective Distillation (TMPD), gives the student richer supervision across time. Instead of reusing one fixed teacher output at every timestep, TMPD creates different but semantically consistent teacher views by applying lightweight random masks to teacher features. This produces a set of diverse temporal supervisory signals from a single ANN teacher, effectively recovering the benefits of multi-teacher supervision without actually training multiple teachers.
The intuition is straightforward. Different timesteps in an SNN reflect different states of evidence accumulation, so it is more natural to supervise them with slightly different perspectives rather than forcing them all toward the same static target.
One Mind: Temporal Progressive Distillation
The second component, Temporal Progressive Distillation (TPD), focuses on truncated inference. In practice, especially on neuromorphic hardware, we often want to stop inference early to reduce latency and energy use. But stopping early can hurt accuracy.
TPD addresses this by progressively aligning the cumulative prediction at earlier timesteps with the fuller, more stable prediction that emerges later. Rather than treating each timestep in isolation, it encourages the model’s partial predictions to move steadily toward a shared final decision. That is the “one mind” idea: regardless of when inference stops, the prediction should remain consistent.
Why the method is interesting
One strength of the paper is that it does not stop at empirical gains. It also provides theoretical analysis for both components.
The analysis argues that TMPD acts as an implicit regularizer by perturbing teacher logits across timesteps, which reduces harmful gradient correlation and leads to a lower final error floor than conventional temporal-wise distillation. The paper also shows that TPD gives stronger guarantees under truncated inference than standard neighbor-step or no-consistency baselines. Together, the two components target complementary parts of the temporal error: TMPD improves full-length accuracy, and TPD reduces the accuracy drop when inference is truncated.
What the experiments show
The results are strong across both standard and large-scale benchmarks.
On CIFAR-10, CIFAR-100, and ImageNet, MEOM consistently outperforms prior directly trained and distillation-based SNN methods across architectures and timestep budgets. For example, on ImageNet at T = 4, MEOM reaches 71.64% top-1 accuracy with ResNet-34 and 76.77% with a spiking transformer (S-8-384), surpassing prior SNN baselines under the same timestep budget.
On CIFAR-100, the gains are especially notable. With ResNet-19, MEOM reaches 83.22% at T = 6, and the paper notes that it slightly outperforms the ANN teacher in that setting.
The method also performs well when inference is truncated. When models trained with six timesteps are evaluated using fewer steps, MEOM retains the highest accuracy across truncation points, showing that the “one mind” principle is not just conceptual but practically useful.
Ablation studies further support the design choices. The paper shows that using both TMPD and TPD together gives the best results, and that simple random masks perform better and more stably than learnable masking alternatives such as parameter, gating, or Gumbel-sigmoid masks.
Efficiency and practical implications
MEOM does slightly increase firing rate, energy, and training time compared with simpler baselines, largely because TMPD introduces additional masked teacher computations. But the paper reports that this comes without increased GPU memory, and remains much cheaper than training multiple teachers. That trade-off is important: the method adds training complexity in exchange for stronger performance and better time-flexible inference.
For neuromorphic AI, that matters. A model that performs well only when allowed to run to completion is less useful in real deployment settings. A model that remains accurate even when stopped early is far more practical.
Why this work matters
The broader contribution of MEOM is that it treats time as a first-class part of the learning problem. Instead of asking a temporal model to learn from static supervision, it gives the model temporally diverse guidance and a mechanism for maintaining consistency across partial and full predictions.
That combination appears to be the key reason the framework works so well. It improves accuracy at full length, preserves performance under truncation, and brings SNN training closer to the realities of efficient deployment.
For brAIn Lab, this paper marks a clear step toward making spiking neural networks not just biologically inspired and energy efficient, but also more accurate, more robust, and more usable in practice.